EyeBench: Predictive Modeling from Eye Movements in Reading
Omer Shubi *,
David R. Reich
*,
David R. Reich
 *,
Keren Gruteke Klein,
Yuval Angel,
Paul Prasse,
Lena Jäger,
Yevgeni Berzak
*,
Keren Gruteke Klein,
Yuval Angel,
Paul Prasse,
Lena Jäger,
Yevgeni Berzak
*,
David R. Reich*,
Keren Gruteke Klein,
Yuval Angel,
Paul Prasse,
Lena Jäger,
Yevgeni Berzak
Technion
University of Zurich
University of Potsdam
Overview
A standardized framework for decoding cognitive and linguistic information from eye movements during reading.
Tasks & Datasets
7 challenging prediction tasks based on 6 eye tracking datasets, covering both reader properties and reader–text interactions.
Data Harmonization
Preprocessed, aligned text–gaze data in a unified format, so you can focus on modeling instead of cleaning and feature engineering.
Modeling & Evaluation
15 implemented models evaluated under 3 realistic generalization regimes - unseen reader, unseen text, unseen reader & text.

~1.5K
Participants

~4.7M
Fixations

~110K
Words

~31K
Reading Trials

An example of eye movements over a passage.
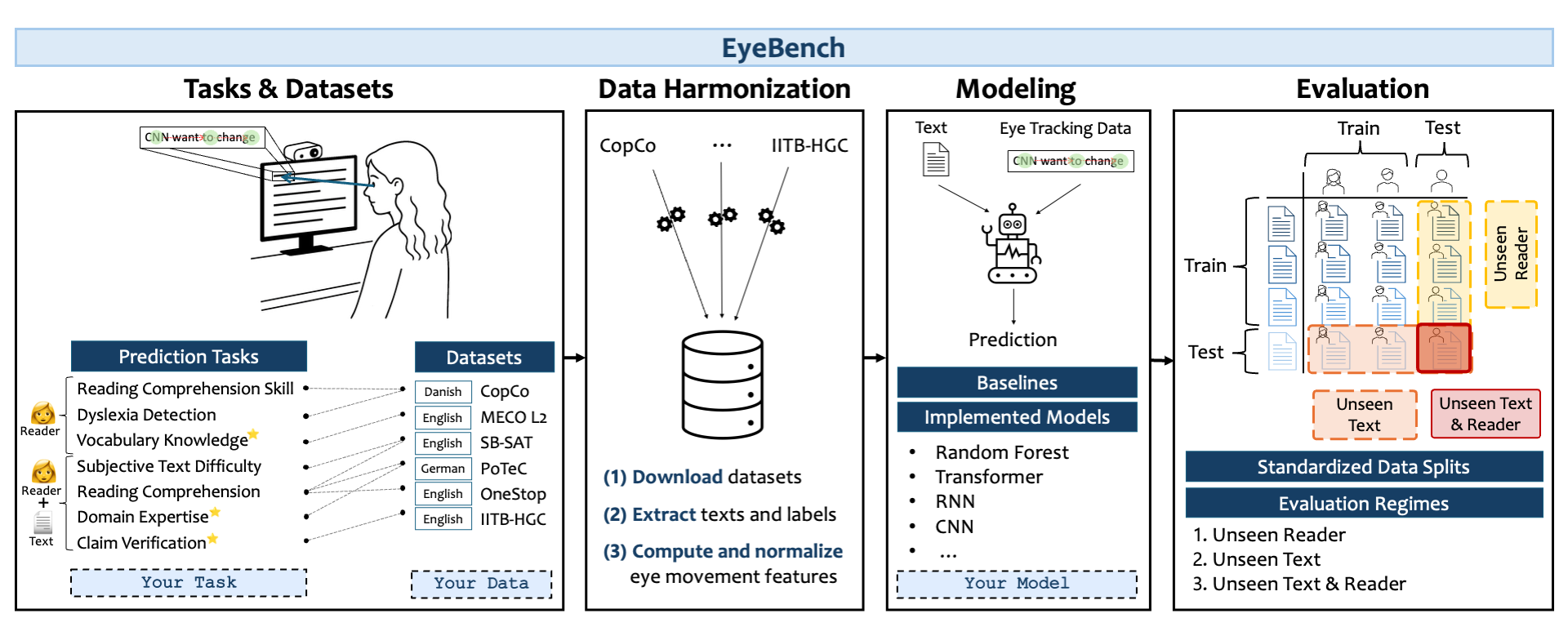
Overview of EyeBench v1.0. The benchmark curates multiple datasets for predicting reader properties (👩), and reader–text interactions (👩+📝) from eye movements. ⭐ marks prediction tasks newly introduced in EyeBench. The data are preprocessed and standardized into aligned text and gaze sequences, which are then used as input to models trained to predict task-specific targets. The models are systematically evaluated under three generalization regimes — unseen readers, unseen texts, or both. The benchmark supports the evaluation and addition of new models, datasets, and tasks.
BibTeX
@inproceedings{shubieyebench,
title={{EyeBench}: {P}redictive Modeling from Eye Movements in Reading},
author={Shubi, Omer and Reich, David Robert and Gruteke Klein, Keren and Angel, Yuval and Prasse, Paul and J{\"a}ger, Lena Ann and Berzak, Yevgeni},
booktitle={The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track}
year={2025},
url={https://openreview.net/forum?id=LhbYJJ3MFd}
}